
We’ve had people ask us, “Is observability really about monitoring”, so we decided that was a good topic for this month. This goes along with our previous blog posts about the different stages in the holistic testing model and how testing fits in the cycle.
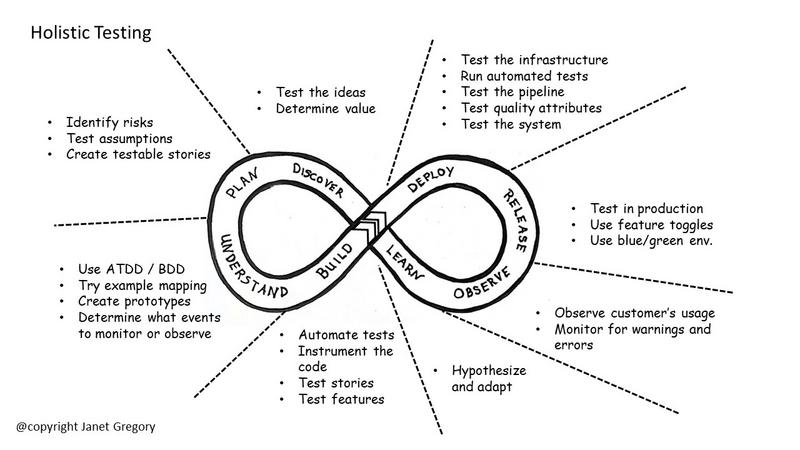
Both monitoring and observability use telemetry (measurements for data collection) from an application’s code to understand production system behavior. However, there are important distinctions between the two.
Monitoring is about looking for behavior that we expect. We collect log data, and then use monitoring tools to aggregate it, analyze it, and produce dashboards and alerts. We compare the actual data with what we expected. Monitoring is about predictable failures; it lets us see deviation from expected behavior.
Observability is about the behavior that we didn’t expect or couldn’t anticipate. Today’s complex systems fail in complex ways. Stuff happens – and we need to ask questions that we didn’t expect to ask. One of the best ways to know if you have observability is to answer this question: “Do you have to add new instrumentation to the code and redeploy it to diagnose a problem?” Practicing observability means being able to diagnose a problem without that step.
We’re borrowing a visual from James Lyndsay with a slight nuance switch to show the difference.
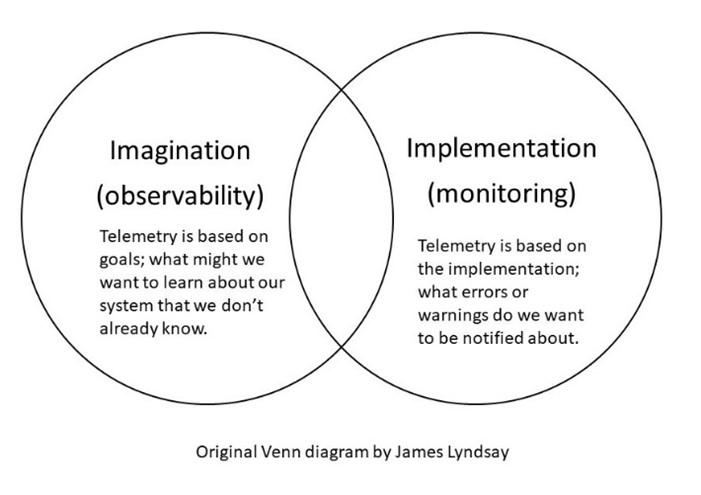
Note: The original Venn diagram is available as a download from https://www.workroom-productions.com/why-exploration-has-a-place-in-any-strategy/. We encourage you to read it.
Many teams have used monitoring tools for many years but find that their customers may still feel pain even as their monitoring dashboards show a healthy picture. Hopefully, we did all the important testing before releasing a change anticipating what might happen in production, and we might even have done chaos engineering to explore different types of failures in a controlled way.
From experience, we know we cannot think of everything, but we know that we have to be ready for anything. That is we capture all the information we possibly can and use specially designed tools to analyze it quickly – to diagnose problems quickly. We like to think of it as an early warning system. That is what we call observability.
In her new Test Automation University course, Introduction to Observability for Test Automation, Abby Bangser includes a terrific summary of the monitoring vs. observability. Some important highlights are:
- With monitoring, we have a way to track, identify and lock in behavior across a wide diversity of systems and we can do this in a fairly standard way.
- Monitoring can consistently alert on changes to the baseline.
- Observability aims at supporting the unknown.
- An observable system is one that can answer new, unique and complex questions without delay.
- Observability provides specifics to triage and creatively explore even highly specific impact bugs.
You can get in-depth information about observability in Abby’s course, including the origin of the term. Observability is one important tool among many to learn how our customers use our product, what pain points they have, what features they might still need. When we build our software features, we need to build in the telemetry for monitoring, observability, and analytics. All of this enables us to respond quickly to production issues, no matter how many or how few users feel the impact.